この記事で言いたいことは1つだ。AI起因のセキュリティ事故は急増している。だが、本当に危険なのは「コードの脆弱性」ではない。
データを追えば、AIが書いたコードのCVEが急増していることがわかる。しかし現場でAI開発を続けてきた私の実感は違う。最も多くのデータが漏れる穴は、コードの中ではなくコードの外——業界のルールを知らないまま個人情報や機密を扱う「ドメイン知識の欠如」にある。本記事では、2026年の一次データと私自身の経験から、その真の脆弱性を解説する。
数字は「AIのコードが危ない」と叫んでいる
まず、事実を整理する。感覚論ではない。
以前、AppleがVibe Codingアプリを拒否し始めたという記事で、「AI生成コードの45%に脆弱性がある」と書いた。あれから、さらに深刻なデータが積み上がった。公式にカウントされるCVE(共通脆弱性識別子)が、急増している。

- AI起因のCVEは、2026年1月の6件から3月の35件へ。わずか2ヶ月で約5.8倍に増えた。3月時点の累計は74件に達している(SQ Magazine / Arnica)。
- 2026年2月、Vibe Codingだけで作られたSNS「Moltbook」が侵害された。設定ミスのデータベースから、150万件の認証トークンと3万5,000件のメールアドレスが露出していた(Forbes)。
- GitHub Copilotを使うリポジトリの6.4%が秘密情報を漏らしている。AIを使わないリポジトリの4.6%より40%も高い(Kusari)。
そして、見逃せない変化がある。攻撃対象が「AIが書いたコード」から「AIツールそのもの」に広がった。
Copilotでは、プルリクエストの説明文に仕込んだ隠しプロンプトから、リモートでコードを実行できる脆弱性が報告された(CVE-2025-53773、深刻度CVSS 9.6)。さらに「Comment and Control」と名付けられた攻撃手法は、Claude Code・Gemini CLI・GitHub Copilot Agentのすべてに効くことが確認されている(SecurityWeek)。私が毎日使っているClaude Codeも、例外ではない。
数字だけ見れば、結論はシンプルに見える。「AIのコードは危ない。だから検証しろ」——と。
だが、CVEは氷山の一角だ
ここで立ち止まりたい。
CVEやシークレット漏洩は、いずれツールとプロセスで潰せる問題だ。SAST(静的解析)を回す。依存パッケージを検証する。エージェントの権限を絞る。これらは前回の記事で書いた「品質ゲート」の話であり、外部のツールが日々進化している領域だ。
問題は、その先にある。
Moltbookの事故をもう一度見てほしい。漏れた原因は、凝った攻撃コードではない。**「設定ミスのデータベース」**だ。認証トークンが、誰でも読める状態で置かれていた。これはSASTが検出する「コードの脆弱性」ではない。そもそも、その人が「認証トークンはこう保管すべきだ」というルールを知らなかった——それだけの話だ。


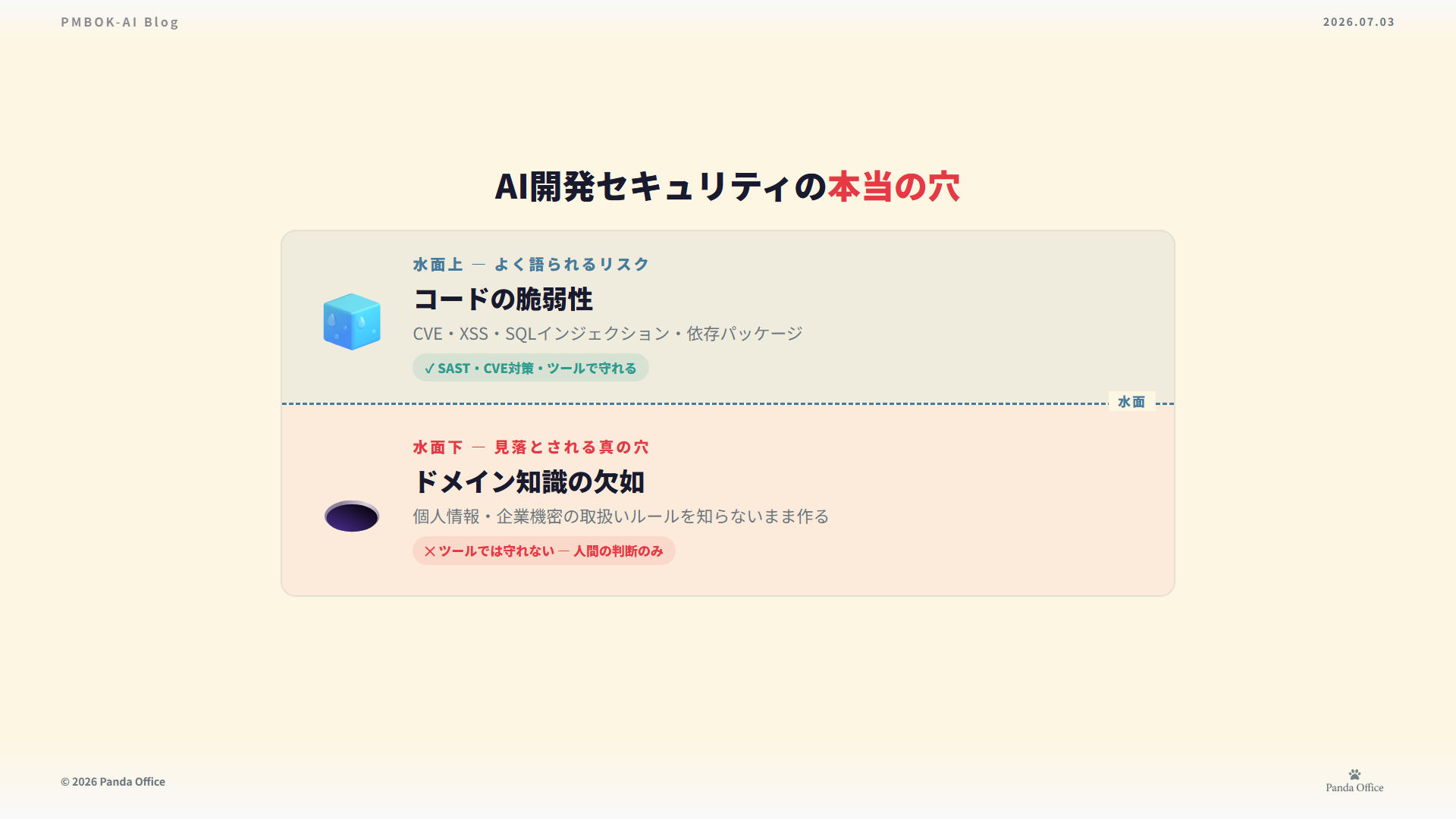
私が言いたいのはこうだ。AI開発のセキュリティには、2つの層がある。

- 上層=コードの脆弱性:SQLインジェクション、XSS、依存パッケージ。SASTやCVE対策など、ツールで守れる
- 下層=データの取扱い:誰の、何のデータを、どこに、どれだけの期間、誰がアクセスできる形で保存するか。ドメイン知識でしか守れない
上層ばかりが記事になり、ツールが売られる。だが、実際に企業や個人を破滅させるのは、下層の無知だ。個人情報を暗号化せずに保存する。退職者のアクセス権を消し忘れる。取引先の機密を、規約で禁止されたAIサービスに投げる。これらはコードの脆弱性ではない。ルールを知らないことによる事故だ。
なぜ「ドメインを知らない」と守れないのか
ここが本題だ。なぜ、ドメイン知識がないとデータを守れないのか。
答えは、プロンプトを磨くな、経験を積めで書いた原則と同じだ。「何を守るべきか」を知っているのは、その業界を経験した人間だけだからだ。
業界ごとに、データの扱いはまったく違う。
- 医療:患者データは、そもそも保存場所と保持期間が法令で細かく縛られている
- 金融:取引データは暗号化・監査ログ・アクセス制御が前提。1つ欠けても違反になる
- 人材・EC:本人同意なしに個人情報を第三者へ渡せない。同意の取り方まで決まっている
これらは、コードを書く前に決まっている制約だ。知らなければ、AIに「安全に作って」と頼んでも意味がない。AIは、あなたが知らないルールを補ってはくれない。 間違った前提を渡せば、間違ったまま完璧に動くコードを返してくるだけだ。
私自身、現場を知らない設計がいかに危ういかを、WMS(倉庫管理)の案件で痛感している。管理部署が半年かけた設計は、現場に行けば5分でわかる破綻を抱えていた。解像度は、現場の経験からしか生まれない。 データの取扱いも、まったく同じだ。その業界で、実際にそのデータを扱った経験がなければ、「守るべき対象」そのものが見えない。
私がコードより先に「ルール」を固める理由
具体的な話をする。
私は今、マレーシアで日系企業向けのAI導入支援サービスを立ち上げている。ここで最初にやったのは、コードを書くことでも、AIツールを選ぶことでもない。マレーシアの個人情報保護法(PDPA)の要件を、先に押さえることだった。
理由はシンプルだ。顧客の個人データをどう扱うかは、1行もコードを書く前に決まる問題だからだ。
- どの国の、どの法律が適用されるのか(マレーシアのPDPAか、日本の個人情報保護法か)
- データをどこのサーバーに置くのか(国外移転に制限はないか)
- どこまでの情報を、どれだけの期間、保持していいのか
- AIサービスにデータを投げること自体が、規約や法令に抵触しないか
これを最初に固めるから、AIへの指示の解像度が上がる。「PDPAに従い、個人データは国内リージョンに保存し、90日で自動削除する設計にしてくれ」——ここまで言えて、初めてAIは正しく動く。逆に言えば、この前提を言語化できない人が作るサービスは、コードがどれだけ堅牢でも、根っこが漏れている。
AI活用で痛感した失敗と教訓でも書いたが、指示の解像度と出力の品質は比例する。そして、データ取扱いにおける解像度は、法令と業界ルールの知識からしか生まれない。ツールでは埋められない。
コードの外を守る5つの確認
では、どうすればいいか。前回の記事で書いた「コードの検証(設計書との照合・セキュリティレビュー・依存パッケージ確認)」は、上層の話だ。ここでは、その外側——データの取扱いを守る5つの確認を挙げる。

- 誰の、何のデータかを棚卸しする:氏名・連絡先・決済情報・取引先の機密。区分を書き出す。区分できないデータは、守りようがない
- 適用される法令・業界ルールを先に確認する:個人情報保護法、PDPA、業界固有の規制。コードを書く前に調べる
- 保存場所・暗号化・保持期間を決める:どこに、どう暗号化して、いつ消すか。無料インフラの初期設定のまま本番に出さない
- アクセス権と退出処理を設計する:誰が見られるか、退職・契約終了時に権限をどう消すか。放置された権限は、時限爆弾だ
- 知らない領域は、ドメイン専門家に確認する:自分が経験のない業界なら、必ずその業界を知る人に確認する。「AIに聞けばいい」で済ませない
このうち、SASTやCVE対策で自動化できるものは1つもない。すべて、人間がドメインを理解して判断する領域だ。
まとめ:コードは守れても、データは守れない
3行でまとめる。
- AI起因のCVEは約5.8倍に急増し、AIツール自体も攻撃対象になった。だがこれは氷山の一角だ
- 本当に危険なのは、業界のデータ取扱いルールを知らずに個人情報や機密を扱う**「ドメイン知識の欠如」**——コードの外にある穴
- ツールで守れるのは上層だけ。下層は、その業界を経験した人間の判断でしか守れない
明日からできることは1つ。AIにサービスを作らせる前に、**「このデータを、自分は業界のルール通りに扱えているか」**と問うてほしい。答えられないなら、まずそのルールを学べ。あるいは、知っている人に聞け。
Vibe Codingは、個人開発の速度を劇的に上げた。その次のステップとして商用開発に進むとき、コードの品質以上に問われるのが、このデータを扱う責任だ。お金をもらうことは、責任だ。 そして責任は、コードの外側から始まる。
コードは、AIとツールで守れる時代になった。だがデータを守れるのは、ドメインを知る人間だけだ。これが、PMBOK-AIが「Human-in-Command」と呼ぶ思想——どこまでAIに任せ、どこで人間が判断するかを決める——の、セキュリティにおける核心である。
参考・出典
- Vibe Coding Security Risks You Can't Ignore 2026(Arnica) — CVE月次推移・Moltbook侵害
- AI Coding Security Vulnerability Statistics 2026(SQ Magazine) — 累計CVE・CVE-2025-53773
- AI Coding Assistants in 2026: 4× Faster, 10× Riskier(Kusari) — シークレット漏洩率
- Claude Code, Gemini CLI, GitHub Copilot Agents Vulnerable to Prompt Injection(SecurityWeek) — Comment and Control攻撃
- Vibe Coding Has A Massive Security Problem(Forbes) — Moltbook事故の詳細
関連記事
- AppleがVibe Codingアプリを拒否し始めた — AI生成コードの品質と品質ゲート(本記事の前編)
- Vibe Codingの先へ|個人開発と商用開発の決定的な違い — 商用AI開発の5フェーズ
- プロンプトを磨くな、経験を積め — 経験が解像度を生む
- 現場に行け — ドメイン理解の現場主義
- AI活用で痛感した失敗と教訓 — 指示の解像度と出力品質
AI開発でのデータ取扱い設計や、業界ルールを踏まえたAI導入のご相談はお問い合わせからどうぞ。Panda Officeのサービス一覧もご覧ください。